Distributed Database Management Systems (DDBMS) represent a fundamental paradigm shift from centralized database architectures, enabling data storage and management across multiple interconnected nodes or sites. This comprehensive analysis examines the intricate architectural frameworks that constitute modern distributed database systems, exploring their core components, various architectural models, and the complex challenges they address in contemporary data management scenarios. The evolution of DDBMS has been driven by the need for scalability, fault tolerance, and geographic distribution of data, leading to sophisticated architectural solutions that balance autonomy, distribution, and heterogeneity concerns while maintaining data consistency and system performance.
Fundamental Components and Infrastructure of DDBMS
Core System Components
The architectural foundation of any Distributed Database Management System rests upon several critical components that work in coordination to provide seamless data management across distributed environments. The primary components include computer workstations or remote devices that form the network nodes, each serving as independent sites within the distributed system. These nodes must operate independently of specific computer system hardware, ensuring platform neutrality and vendor independence across the distributed infrastructure. The distributed nature of these systems demands that each component be capable of autonomous operation while maintaining coordination with other nodes in the network.
Transaction and Data Processing Architecture
The transaction processor (TP) represents a critical software component that operates on each computer or device within the distributed system, responsible for receiving and processing both local and remote data requests. Also referred to as the application processor (AP) or transaction manager (TM), the TP serves as the interface between user applications and the distributed database system, managing the complex coordination required for distributed transactions. This component must handle the intricacies of distributed transaction processing, including coordination with remote sites, maintaining transaction atomicity across multiple nodes, and ensuring proper rollback mechanisms in case of failures.
Data Distribution and Replication Mechanisms
Replication Strategies and Implementation
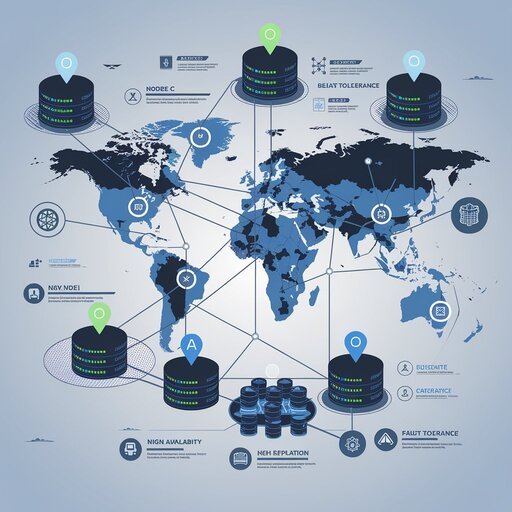
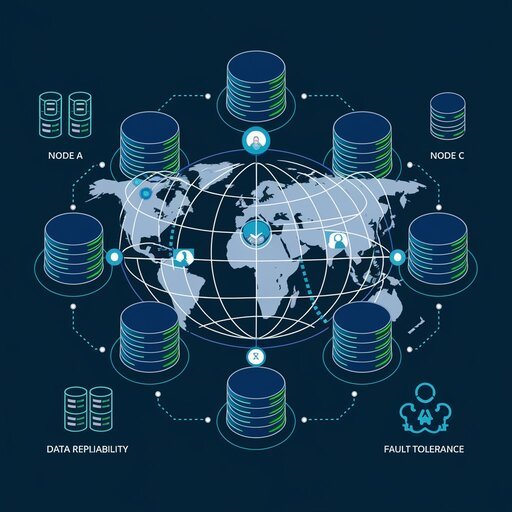
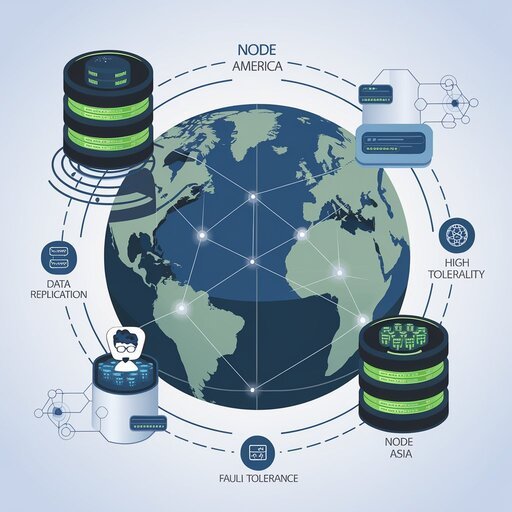
Data replication serves as a cornerstone mechanism in distributed database architectures, enabling the creation of redundant copies of databases or data stores across multiple locations for enhanced fault tolerance and availability. The replication process involves moving or copying data from one location to another, or storing data simultaneously in multiple locations, ensuring that replicate copies remain consistently updated and synchronized with the source database. This approach addresses critical concerns in distributed systems, including data availability, fault tolerance, and performance optimization through reduced access latency.
Fragmentation and Data Distribution Patterns
Data fragmentation represents a critical aspect of distributed database architecture, involving the strategic division and distribution of data across multiple nodes in the network. While traditional fragmentation concepts focus on storage optimization, distributed systems must address logical fragmentation patterns that optimize query performance and minimize network communication overhead. The fragmentation strategy directly impacts the efficiency of distributed query processing, as poorly designed fragmentation can lead to excessive inter-node communication and degraded system performance





















3 Responses
Really good for BSCS students
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.